-
全部

近日,中国科学院信息工程研究所王鑫课题组在本体构建与融合、知识图谱领域取得科研成果。论文《SCOPE and SCION: Benchmark and Auditable Pipeline for Schema Induction and Fusion from Text》被A类会议ICML2026(The Forty-Third International Conference on Machine Learning)录用。ICML(International Conference on Machine Learning)是机器学习领域最具影响力的国际学术会议之一。 在学术地位上,它长期位居谷歌学术机器学习子类排名前列,且被中国计算机学会(CCF)列为最高级别的A类会议。
论文:《SCOPE and SCION: Benchmark and Auditable Pipeline for Schema Induction and Fusion from Text》
本体是基于规则约束的信息抽取和知识图谱构建的重要前置基础。现有大量信息抽取系统默认已有可用的实体类型、关系类型、事件类型和事件角色结构,但在真实场景中,本体设计、跨数据源对齐和长期维护通常成本高、速度慢,且不同数据源或领域之间容易存在不一致。针对这一问题,论文提出了本体构建评测基准 SCOPE(Schema Construction and Ontology Induction Pipeline Evaluation),用于评估从原始文本中自动归纳本体、并进一步与已有本体进行融合的能力。该基准覆盖 24 个公开信息抽取数据源,包括 15 个关系抽取数据源和 9 个事件抽取数据源,并采用仅使用训练集文本的设置,避免方法直接依赖测试标签或人工预设本体。
围绕该基准,论文进一步提出了结构挖掘与规则约束的本体归纳融合框架 SCION(Structural mining and contract-constrained Induction for Ontology constructiON and fusion。 SCION 首先从语料中构建实体、关系、事件和角色等候选空间,再将大语言模型的命名、合并与过滤过程严格限制在该候选空间内,并通过 JSON 契约、证据指针、确定性校验与回退机制保证输出的可解析性、可追溯性和可审计性。在已有基础本体可用的情况下,SCION 还可通过保守对齐和来源追踪机制,将自动归纳得到的本体与已有本体进行融合,从而支持跨源本体复用和知识图谱构建流程的长期维护。
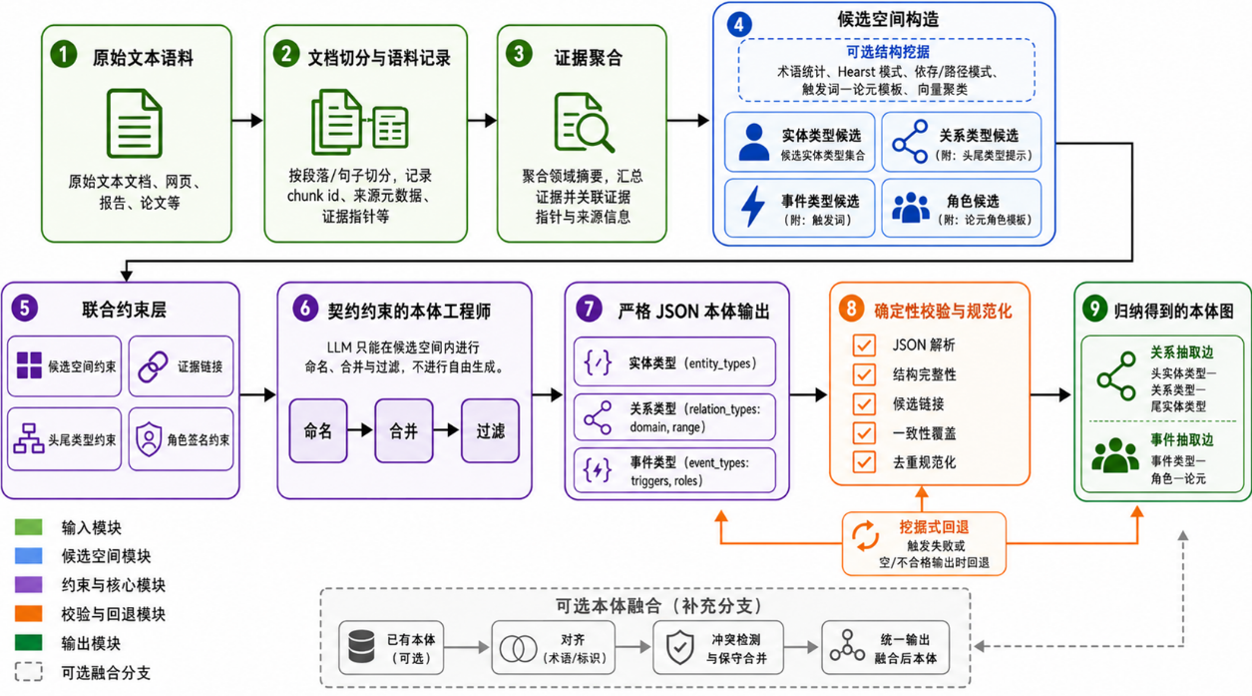
该工作为从原始语料自动构建、评估和本体融合提供了系统化基准与可审计流水线,有助于降低知识图谱工程成本,提升知识图谱构建的自动化、可复现性和跨领域迁移能力。
该文章第一作者为博士生胡淼泊,指导老师为王鑫高级工程师。
附件下载:

